Want to skip to illustrated steps?
There's multiple approaches to fixing mixed content, from using CSP to monitor in real time, plugins for specific platforms & crawling a site externally.
When crawling a site you might find it takes too long to crawl the entire site at once, or there may be too many issues found at once to be actionable. Breaking the site down into logical sections can help here.
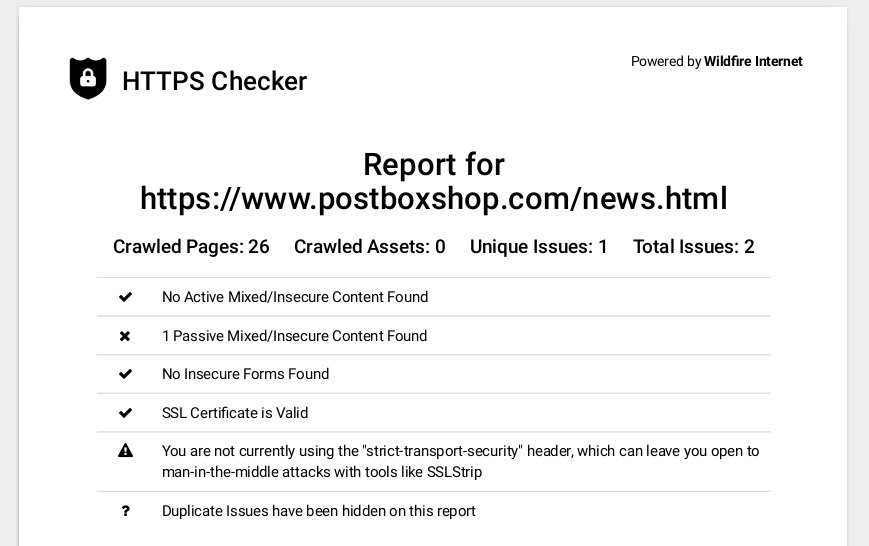
For example, with HTTPS Checker you could scan just through a news/blog section of a site:
Steps:
Set the initial URL to
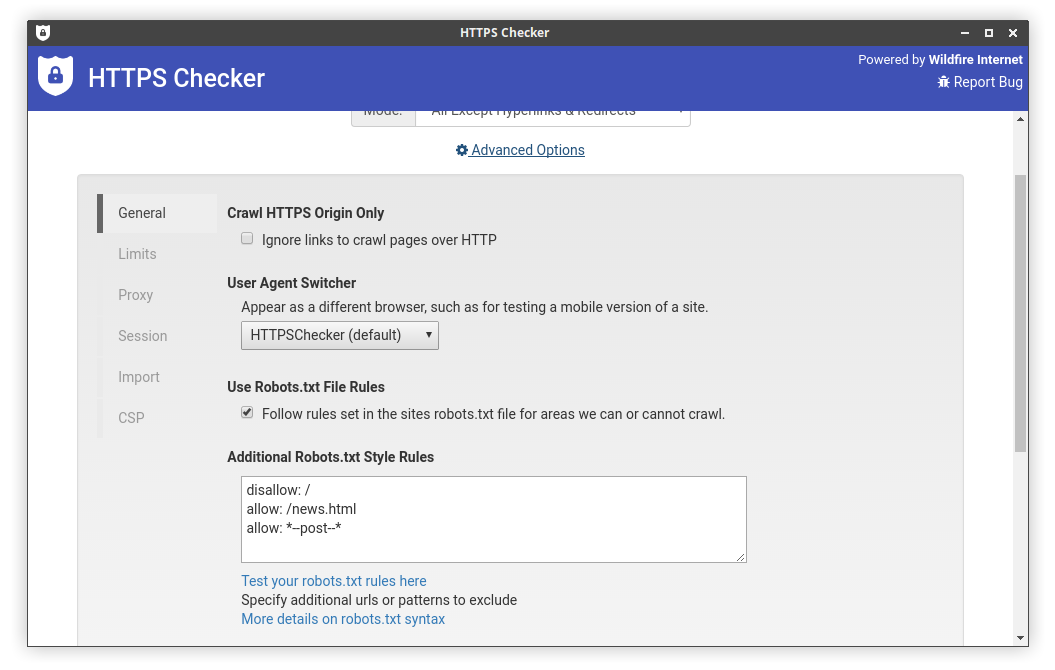
https://www.postboxshop.com/news.htmlSet the additional robots.txt rules (found under Advanced Options) to:
disallow: /
allow: /news.html
allow: *--post--*
The above robots.txt rules state to block everything (disallow: /), except the /news.html page (allow: /news.html) where we will start the scan and allow any pages with --post-- inside the url (allow: *--post--*) as this site uses this in the url structure.
This will then provide a report of just the urls found in those specific sections. This works for directories too such as to allow just a specific directory:
disallow: /
allow: /blog/
You could even do the reverse of this if you'd like by starting from the homepage (https://www.postboxshop.com/), dropping the initial line in the robots.txt as allow: / is implied, and changing the allow lines to disallow like so:
disallow: /news.html
disallow: *--post--*
Illustrated steps:
Initial screen after download & install:
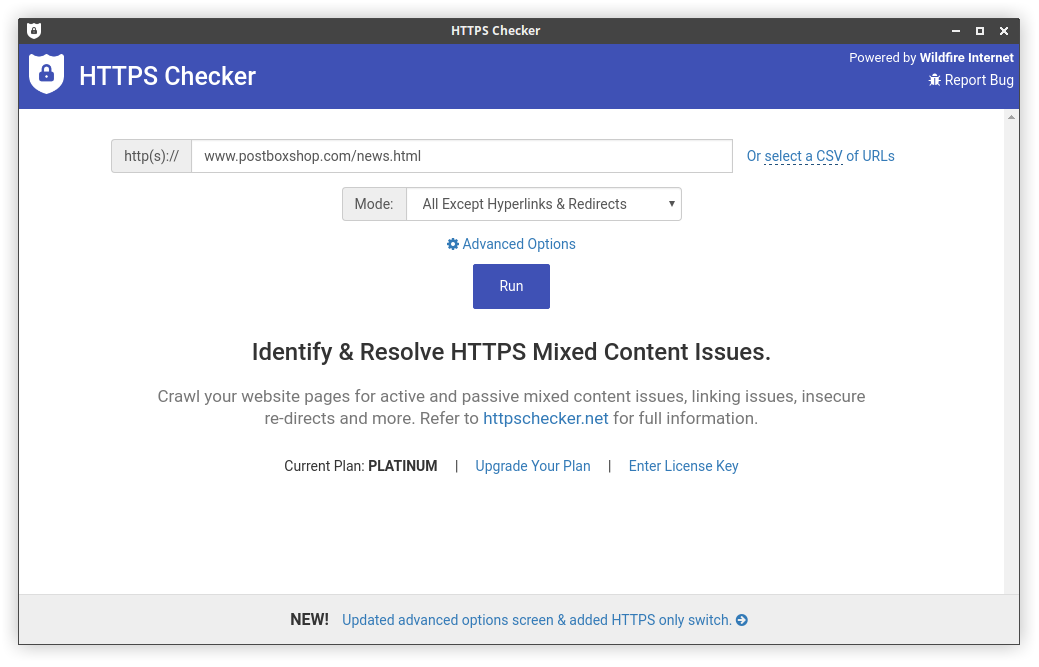
Advanced options - setting additional robots.txt rules:
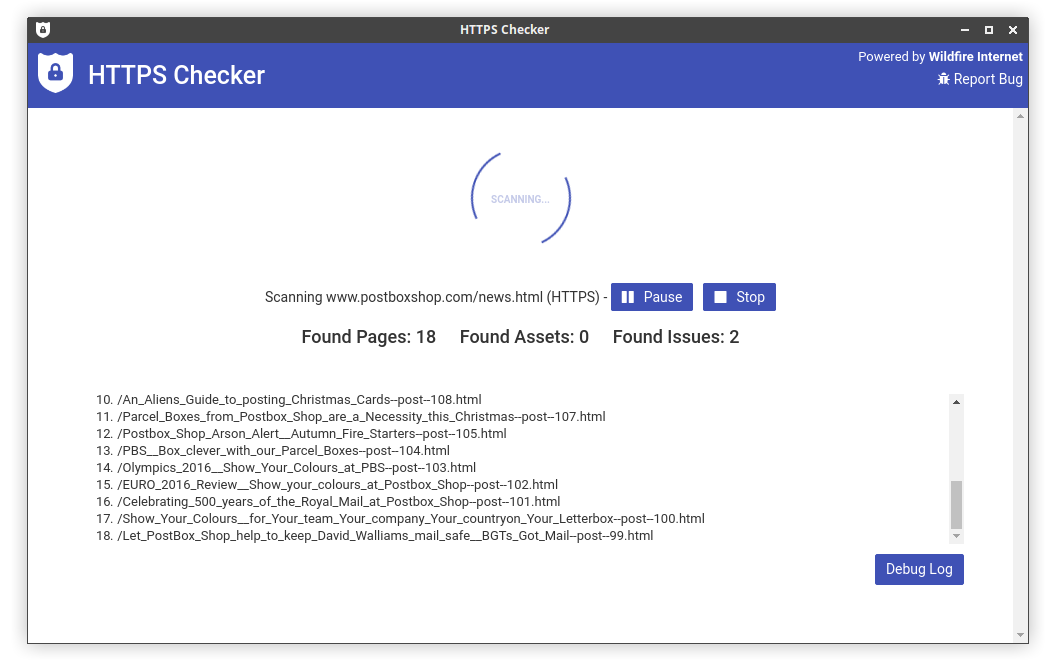
Loading through you can see URL's as they are crawled and check that your robots.txt rules are in use:
Final report screen showing a summary of issues found:
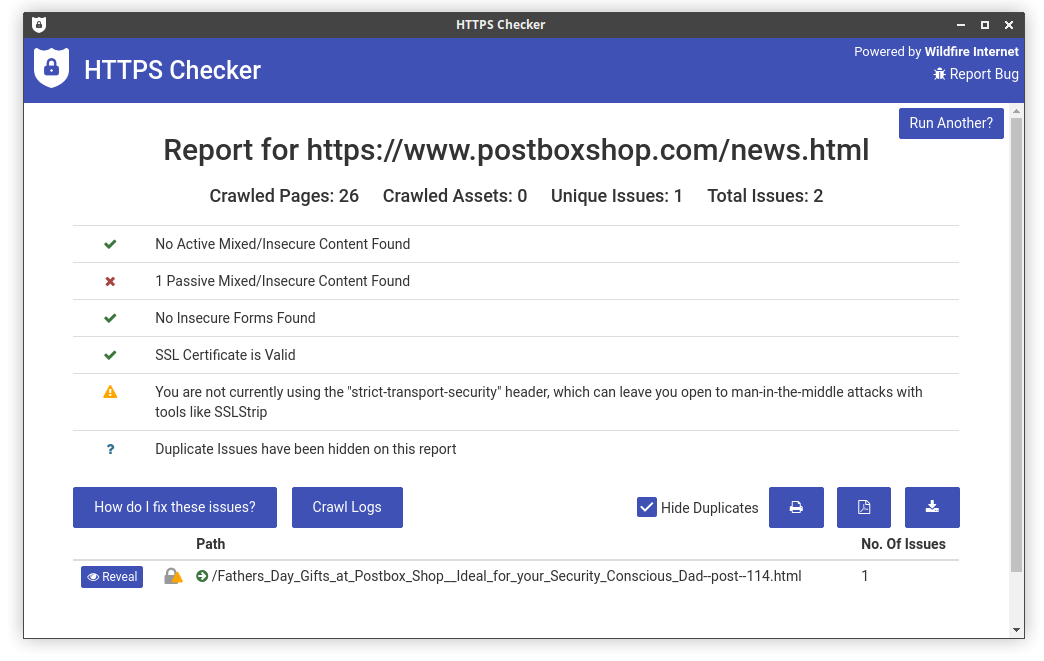
Find the exact html that triggered this warning:
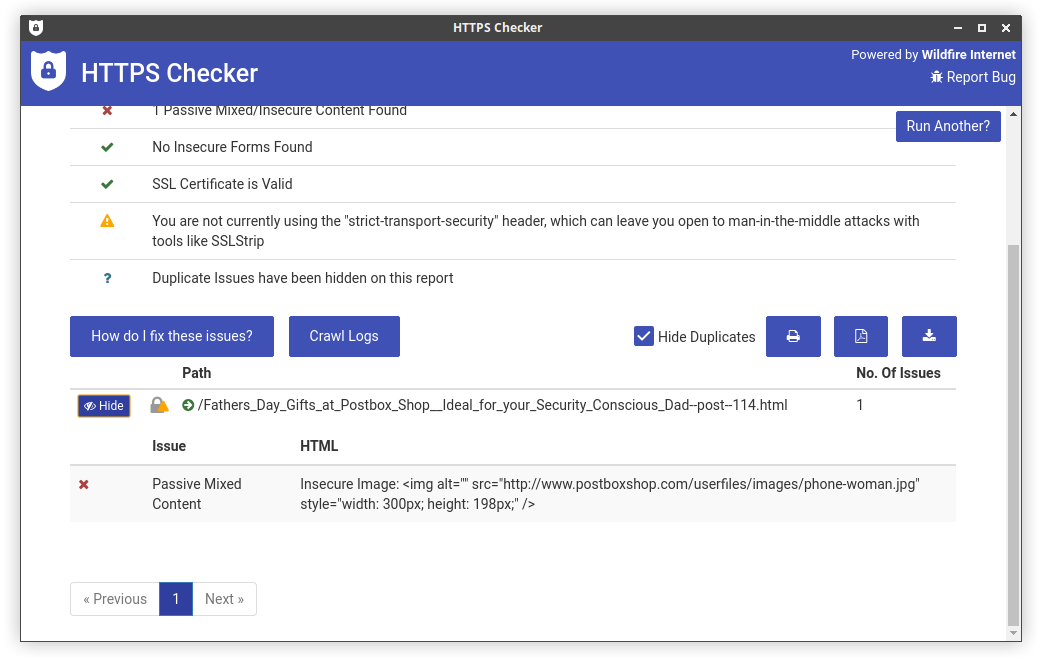
These details are available in CSV / excel format:

6b. A print / pdf version is also available to pass onto management.